In short
- Retries handle transient failures. DLQs handle everything else: permanent errors, broken consumers, bad schemas.
- Without a DLQ, events that exhaust their retries are silently dropped.
- A DLQ stores the full original payload and failure metadata so you can replay after fixing the root cause.
- Not all failures deserve retries. 4xx responses should go straight to the DLQ.
- Alert the moment DLQ depth rises above zero. Silent accumulation is the enemy.
---
Webhook retries are your first line of defense. Transient network issues, brief consumer downtime, a cold start that took too long. Retries handle all of that with exponential backoff. The retry best practices guide covers how to structure them.
But retries only work if the failure is temporary. When a consumer is genuinely broken (schema mismatch, logic bug, permanent authentication failure), retries just generate noise. You need somewhere for those events to land that is not the floor.
That is what a dead letter queue is for.
---
1. Why retries alone are not enough
Most webhook platforms retry a fixed number of times over a window of hours. After the last attempt fails, the event is gone. No trace, no recovery, no replay.
For low-stakes events, that might be acceptable. For anything that matters: payments, provisioning, state transitions. Silent data loss is not.
A DLQ is the safety net at the bottom of the retry ladder. When an event exhausts its retries, it moves to the DLQ instead of disappearing. The payload is preserved. The failure history is attached. And when you fix the root cause, you can replay the event as if it just arrived.
The retry ladder handles the recoverable failures. The DLQ handles everything else.
---
2. What goes into a DLQ (and when)
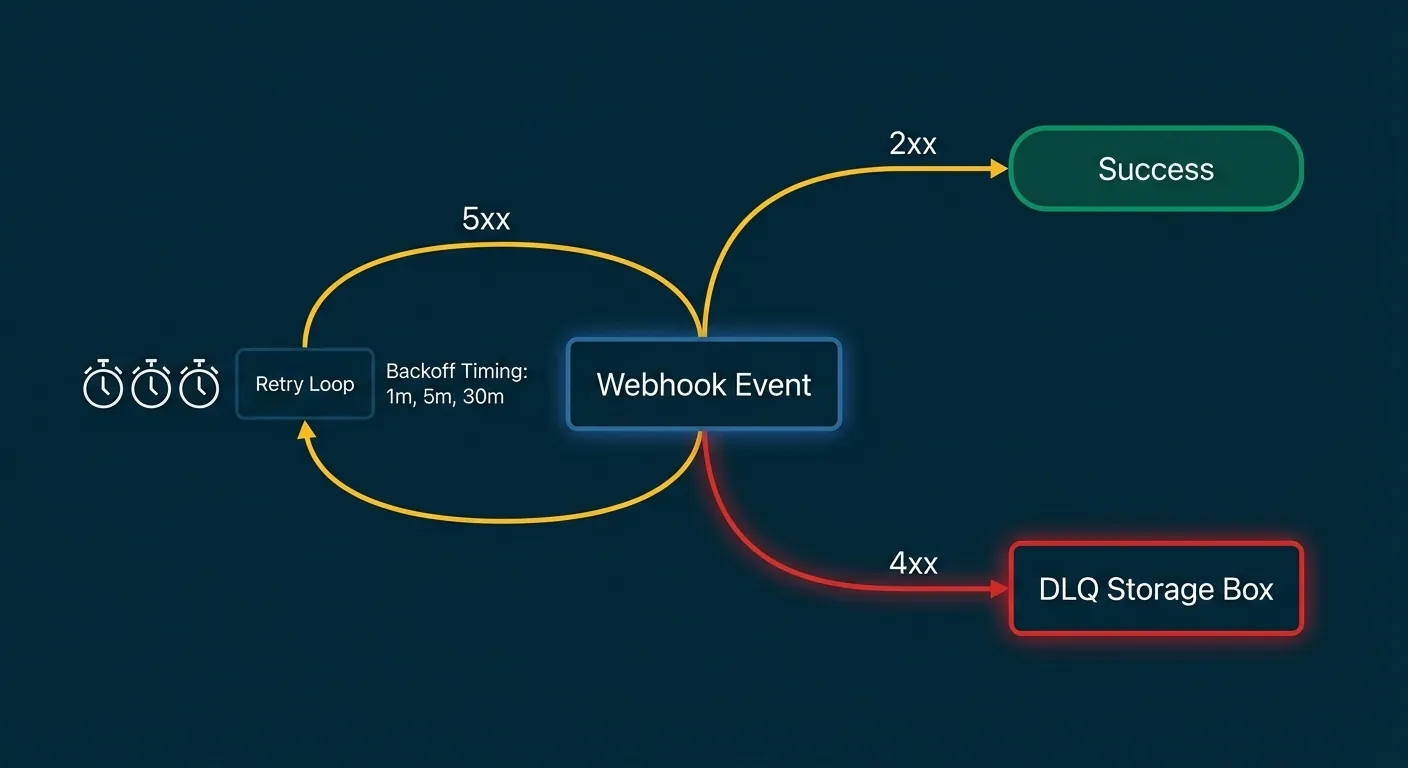
Not every failure should be retried before landing in the DLQ. The HTTP status code tells you which path to take.
| Response | Retry or DLQ? | Reason |
|---|---|---|
| 2xx | Success, no action | Delivered |
| 429 | Retry with backoff | Rate limited, try later |
| 5xx | Retry with backoff | Server error, may recover |
| 400 | DLQ immediately | Bad payload, won't fix itself |
| 401 / 403 | DLQ immediately | Auth failure, needs human fix |
| 410 | DLQ immediately | Endpoint gone, stop retrying |
| Timeout | Retry with backoff | Transient, usually recoverable |
The key insight: 4xx errors are your consumer telling you something is wrong with the request itself. Retrying a 400 ten times does not make it valid. Move it to the DLQ fast, before you waste retry budget.
Permanent errors like 410 should also circuit-break the endpoint entirely. No point delivering to a destination that no longer exists.
---
3. What to store in the DLQ record
A DLQ record that only contains the original payload is not very useful when you are trying to understand what went wrong. Store everything you need to diagnose and replay.
{
"id": "dlq_01h9x2k3m4n5p6q7r8s9t0",
"event_id": "evt_01h9x2k3m4n5p6q7r8s9t0",
"event_type": "payment.failed",
"endpoint_id": "ep_01h9x2k3m4n5p6q7r8",
"destination_url": "https://your-agent.example.com/webhooks",
"created_at": "2026-03-09T09:14:22Z",
"payload": { ... },
"failure_reason": "http_4xx",
"failure_code": 400,
"retry_count": 0,
"attempts": [
{
"attempted_at": "2026-03-09T09:14:22Z",
"status_code": 400,
"response_body": "Invalid signature format",
"latency_ms": 142
}
]
}The attempts array is particularly useful. When you replay, you want to know exactly what the consumer returned, not just that it failed.
---
4. Replaying from the DLQ
Replay is the whole point of a DLQ. But replaying without care can cause more problems than it solves.
Before you replay anything:
- Fix the root cause first. Replaying into the same broken consumer just refills the DLQ.
- Filter before you bulk replay. If only
payment.failedevents are affected, replay those. Not everything. - Rate-limit replay. Replaying thousands of events at once can overwhelm a consumer that just came back online. Use the same retry rate limits you would for normal delivery.
- Expect ordering issues. Replayed events arrive after the events that came in after them. Your consumer needs to handle out-of-order delivery gracefully. Idempotency keys are your friend here.
Hookwing lets you replay individual events or bulk-replay by endpoint, event type, or time range via the API. Dead letter queue functionality is on the roadmap.
---
5. Alerting on DLQ depth
A DLQ you are not watching is just a different kind of silent failure.
The most important alert: fire immediately when DLQ depth rises above zero. Not when it hits 10. Not when it hits 100. Any item in the DLQ is an event that did not deliver. That is worth knowing about the moment it happens.
Beyond the depth alert:
- Age of oldest DLQ item. If items are aging past 24 hours, no one is looking at the queue.
- Failure reason distribution. A surge in 401s means your signing key changed somewhere. A surge in 400s means your schema drifted.
- DLQ inflow rate. Sudden spikes indicate a consumer deployment went wrong.
For agents operating unattended, DLQ metrics should be surfaced programmatically. Use the delivery observability API to pull DLQ stats into your agent's health checks, not just a dashboard no one is watching.
---
The reliability stack
A production-grade webhook setup has three layers working together:
- Retries with backoff: handle transient failures automatically
- Dead letter queue: capture everything retries could not fix
- Replay: recover without data loss once the root cause is resolved
Each layer covers the gaps the others leave. Without the DLQ, retries are a best-effort system. With all three, you have a recovery path for every class of failure.
---
Build reliable webhooks with Hookwing
Hookwing handles retries and replay out of the box, with dead letter queues on the roadmap. Clear delivery visibility and production-safe recovery workflows from day one.
Start free. No 2FA, no CAPTCHA. Or go straight to the getting started guide and API docs.